
Clipping
There seems to me no better way to begin this discussion than with an epistemological thought experiment (as is the case with most discussions). Consider what you heard in the “epiphone” to this essay[1], which is hiss from a digitization of recordings of Vachel Lindsay, originally made on aluminum records in 1931. It likely sounded like noise, and it is—to human auditory perception. But what if there is a pattern in this noise that is imperceptible to the human ear but recognizable to so-called machine listening? Consider the sample above from the Lindsay, alongside this sample of leading “noise” from digitizations of Harriet Monroe from the same series, alongside this one from the James Weldon Johnson recordings. I’ve been listening to several hours of audio from this series and have come to think that the noise from each of the recordings sounds similar, in the most impressionistic way possible. But what if there is a common pattern in this noise that is recognizable and comparable by a machine? If that were the case, we would be able to take steps toward determining the provenance of poetry recordings based on vestigial artifacts from the materiality of their recording media. And this is exactly the project I am pursuing as part of my participation in the HiPSTAS initiative.
To take a step back, the idea for this project came to me while I was working on the primary focus of my research, the aforementioned Contemporary Poets Series, a series of recordings of poets made at Columbia University in the 1930s and ‘40s. The collection, one of the first archives of poetry audio, was recorded on aluminum records. In the process of editing the recordings, most of which were heretofore unreleased, I noticed that various sections of the recordings had been later distributed by record labels like Caedmon and had found their way into PennSound via digitizations of their respective records (the Lindsay is a good example of this—scroll down to see the Caedmon record). While my archival work has led to confirmation of the provenance of these recordings, it also raises the question about what other recordings from this series exist in PennSound unbeknownst to us (I have been building on Thai Jones’s work to construct a bibliography of this series, but work remains to be done). For example, I had previously posited that the Gertrude Stein recordings in PennSound are from the CPS, based on archival scholarship.[2] What if there were a way to confirm this, and to locate other recordings from the CPS in PennSound, by using machine listening to conduct pattern recognition on the ubiquitous hiss in these recordings?
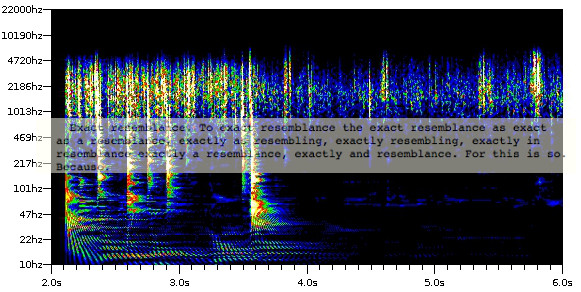
I set about this project, which has been funded thanks to a grant from the Penn Digital Humanities Forum, using the Adaptive Recognition with Layered Optimization (ARLO) tool that you will hear about frequently in this commentary series. ARLO was developed as part of the HiPSTAS initiative led by UT Austin Professor Tanya Clement and is able to query audio archives using sound as a parameter. In other words, ARLO is a machine listening tool that can identify patterns in audio, performing “distant listening,” as Tanya has termed it. Of course, the allusion here is to the Morettian “distant reading.” At this point in time, I am just getting started with the project. I’ve loaded the Lindsay recordings into ARLO and am working with David Tcheng of the HiPSTAS team to perform unsupervised learning on these recordings. The figure here is a spectrogram of the noise from a Lindsay recording, taken from ARLO.
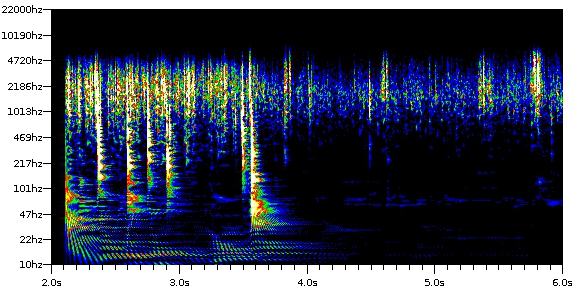
The next step will be to load in some of the Monroe and the Johnson to see if ARLO sees any commonality in the noise between them. If so, we could then move on to testing recordings of Lindsay distributed on the Caedmon record to see if the pattern survived the multiple transcodings. Finally, if all of this proved successful, we could search the entire PennSound archive for recordings that bear the watermark of this particular recording device. Of course, there are many mitigating factors to consider, including whether noise was introduced by the recording medium or the playback medium.
While it remains to be seen whether this research will be successful and if it’s even technically possible, I think it’s worth covering the implications should this experiment turn out to be a success. Most obvious is the value to phonotextual history. In other words, it is valuable to the scholarship to know where recordings came from, and this research could facilitate this process. But further this course of study might help archivists to address the question of how much editing should be done to sound files before they are distributed. For example, it would not be difficult to lessen the hiss in the Lindsay recordings in order to further foreground his speaking voice. But doing this would destroy data, including possibly valuable and searchable data about the history of this recording. There is much more to be said of the practical implications of this research, which I hope to cover in a future post.
And beyond the potential practical effects of being able to determine provenance computationally, there are several theoretical questions that this research opens, including the question of the ontology of the sound recording. Modern technology has greatly disrupted our ability to define what a sound recording is (cf the work of the First Sounds team and also the IRENE software used by Harvard's Woodberry Poetry Room to visually digitize broken records). But each of these disruptions (sound recorded on paper, the synesthetic visualization of sound on a record) implies sound as a singular, discrete entity. If recordings of poets (or any recording really) were to bear recognizable watermarks of their respective births and each subsequent transcoding, then each recording is intrinsically historicized and somewhat contextualized: the recording becomes an encoded lineage of its history, a sort of encapsulated DNA strand. The hiss we heard above then becomes a kind of paratext (para-sound), actual content that lives alongside (if backgrounded) to what we might deem the content proper.
The reason I’ve taken up this project is that my research is underwritten by the idea that recordings of poets must be historicized and contextualized. They must be connected to the social contexts that led to their creation, lest poetry be relegated to the “library,” a metonymy Vachel Lindsay used for poetry in cold storage, severed from life. In short, I hope to show that the noise is content.
The banner image for this post is composed of a spectrogram generated by ARLO and an excerpt from Gertrude Stein's "If I Told Him: A Completed Portrain of Picasso."
[1] I solicited advice from friends on what one would call a sound file that functions like an epigraph embedded atop an essay. My favorite vote was for “epiphone,” no relation to the musical instrument company of the same name. This epiphone is taken from a recording of Vachel Lindsay from The W. Cabell Greet Recordings.
[2] I am currently working on new digitizations of Stein from this series, so will likely be able to confirm this hypothesis without the need for machine listening. That said, these recordings provide a valuable test case.