
Clipping

As readers, writers, students, teachers, or scholars of poetry, many of us have 'first-encounter' stories — hearing Poet X read for the first time; copying neglected Caedmon LPs in the library basement; borrowing a thrice-dubbed cassette of the Black Box Magazine or New Wilderness Audiographics; exploring the personal collection of a generous friend, poet, or teacher. In the days before the web, one might infer the performativity of David Antin, Jerry Rothenberg, Charles Olson, Anne Waldman, or Amiri Baraka through books like Technicians of the Sacred or Open Poetry or envision the scene of a raucous Beat coffeehouse reading, poet jamming with a jazz quintet — but recordings could be scarce. In place of the pleasurable frustration involved in sounding out a Futurist or Dada poem from its suggestive but underdetermined visual text — the reader seeking to hear a poem in 2015 will search online archives like PennSound or Ubuweb. For teaching, the segmented poems accessible there may be played for a class and discussed almost as easily as we might call up a poem from any print anthology or Google it.
Yet in the move from the economies of the limited-pressing LPs or dubbed audio cassettes to the virtual shelves of Pennsound (with something approaching 100,000 MP3s), we may begin to feel a bit like Thoreau confronted with a bottomless pond. We cannot yet move through audio files the way we might browse a shelf or thumb through bound volumes, allowing our eyes to skim the pages in leaping saccades, taking the measure of page, stanza, or line before pausing to read more closely. So as much as we love the capacious audio archive, it also presents as sort of problem. How do we sound its depths?
Over the last two years, a number of poetry scholars have been involved in a project of exploration, of measuring — a distanced sounding — of repositories and archives of poetry audio, making use of an open-source tool called ARLO as our plummet and line. Initially developed by David Tcheng for ornithological research, ARLO was extended to the poetry world through the NEH-funded HIPSTAS project, which provided access, training, and technical support.[1] At a simplified level, ARLO works by producing images of the audio spectra and then comparing these visualized time-slices with others across a range of pre-selected audio files. In the analysis of bird song, the goal is to find matches that locate particular calls within longer field recordings. This matching process helps the ornithologist find the proverbial needle in the haystack without painstakingly auditing hundreds of hours of audio. Some of the HIPSTAS researchers are interested in comparable problems — identifying and tagging unnoticed elements within a file, such as moments of laughter or applause, or the "audio signature" that marks the provenance of remediated poems, which Chris Mustazza proposes in his Clipping piece “The Noise is the Content.”
A number of avenues present themselves as one begins to work with ARLO in the context of poetry audio analysis. At the outset, we novice users wondered whether ARLO should be recalibrated to respect the kinds of questions poetry scholars are inclined to ask. Or whether we might prefer to develop new lines of inquiry based on the kinds of answers ARLO might fruitfully be expected to deliver. What, after all, did we want to know in the first place?
For my part, I decided to build upon a long-standing interest[2] in the discrepancies and variations in the ways poets perform their own poems, on different occasions, in varied places. In particular, I wanted to compare variant recordings in terms of tempo, loudness, pitch range, tension, rhythm, and voice quality (to adopt widely accepted terms for paralinguistic features of speech)[3]. Rather than looking to find the unnoticed Bobwhite call in a batch of field tapes, I wanted to look at a group of known calls/poems and come to better understand their points of difference and correspondence.[4]
In this respect, my starting point differed from that of some of my poetry colleagues, and from the ornithologists as well, who would be looking for a rare occurence within a mountain-sized stack of data. I did not need to take that path because I was interested in working with poems which I already new were similar; each file was encoded with ID3 metadata that told me the files were recordings of the "same" text. Working with Pennsound, we can preselect files for this kind of query using metadata rather than needing to make the selection through digital analysis.[5]
For many of the more generously represented poets — particularly those who gave regular readings during the portable tape cassette and digital recorder eras — Pennsound provides an interesting corpus of versions to audit. We fans have our favorites, and our intuitive senses of what distinguishes, for instance, the 1956 SF State recording of Howl from the Knitting Factory reading in 1995. But if we're going to take the idea of the performance dynamics of poetry seriously and to make rich use of what the archives and repositories hold, we will want to go beyond or at least to complement the practices of close listening, using tools like ARLO to help.
As the simplest test case, I decided to start with a known set of variant recordings of a single speaker who was speaking/reading from a singular, known text. Recognizing his noted emphases on performance and the availability of multiple readings in Pennsound, I chose to work with Jerome Rothenberg. I remembered first coming upon Rothenberg's poem “Old Man Beaver's Blessing Song” set, as a block text, with the implication that it should be read performatively and, certainly, spoken aloud.[6] Pennsound provides access to three segmented digitizations of Rothenberg's poem as MP3 recordings. The poem itself includes significant internal repetition of verbal content and rhythmic patterns, as the poet performs it with chanted passages, shifts his voice dramatically, and speaks with deliberate pauses and rhythms.

To begin working with ARLO, one selects and uploads the files. ARLO processes them, then one tags segments of a file, adjusts parameters, and runs “queries” against the tagged segments.
In a prior experiment, many HiPSTAS participants explored creating a baseline through random, automated tagging which would select a predefined number of time slices from a given file. For instance, one could identify a 10 minute-long file and then issue the command to mark 100 1-second time slices from that file. In my initial trial using random tagging, the confidence level of the matches was so low as to seem unusable for this line of questioning. So for this case study, I decided to mark the initial segments in a different fashion, listening and using the sound intensity visualization as a guideline to manually flag audible “lines” or utterances. In this case, I was working with the following three files from Pennsound:
Old-Man-Beavers_Sightings_Rockdrill-6_2004.mp3
Old-Man-Beavers-Blessing-Song_UCSD_c-1993.mp3
Old-Man-Beaver's-Blessing-Song_KWH_4-28-08.mp3
Having no particular reason to privilege the oldest recording, I simply selected the 2004 studio recording "Rockdrill" on the basis of its superior recording quality as the baseline against which to measure.
Starting with the collection of manually identified passages from Old-Man-Beavers_Sightings_Rockdrill-6_2004.mp3, and marking every section of the recording (i.e. not sampling), I tagged the 16 utterances (varying from 1 to 11 seconds; averaging 5 seconds in length). One then has the opportunity to calibrate the settings[7] of the ARLO pattern matching. I decided to evenly weight pitch and sound intensity (Pitch weight=.5; Damping=.05) , narrowed the frequency range to account for the digitization of moderate quality analog recordings (300 to 4000 hz); and set a liberal tolerance for matches (match ratio=.4)[8].
Having calibrated the settings in order to effectively ask, as best as I could, which of these samples are most like the others — I then executed the query command for a Supervised Tag Discovery, applying it to the KWH and UCSD files. Despite running on a supercomputer, ARLO takes minutes and sometimes hours to return results of a query. Eventually an interesting picture emerged. Starting from the 16-manually tagged utterances of the Rockdrill reading, the ARLO query produced a set of corresponding candidates from other two files. Next one had to look at the “confidence” rating for each of these matches — how close is the correspondence? ARLO provides this data for each tagged sample produced by this supervised discovery query.[9] Overall, the average confidence for the matches with the UCSD was moderately high (Min=.427; Max=.984; Avg=.637) with only four of sixteen above 70%; but the match with the KWH file was notably stronger (Min=.531.; Max=1.003; Avg=.680) with seven of sixteen above 70%.[10]
Using ARLO to analyze the versioning phenomena among these three files suggests varying degrees of differentiation among the readings, which can be identified through “distant sounding.” One important factor differentiating the three pieces is their length; the Rockdrill performance is just about 90 seconds long from title to the closing (Rothenberg repeats the title); while the UCSD performance is over 40 seconds longer. Where does this additional space come from? Rothenberg does not add any lines, additional repetitions, or a commentary. But as the piece progresses, he interjects longer pauses and prolongs phonemes in a much more exaggerated fashion.
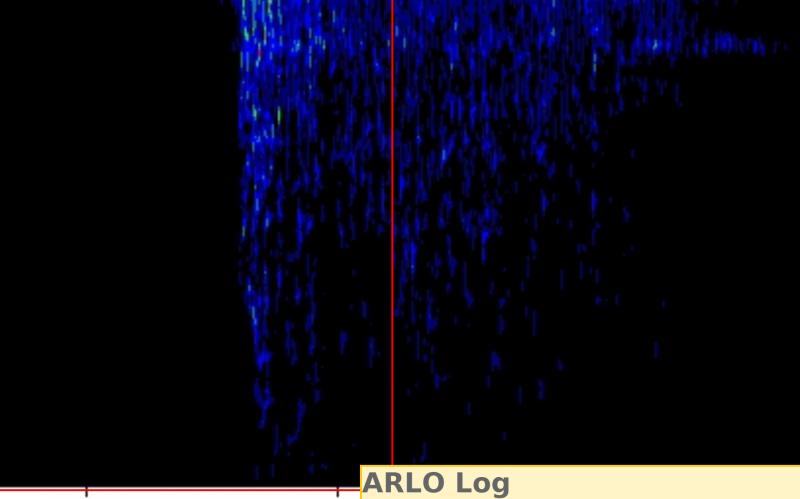
So finally, in the UCSD performance, as Rothenberg moves into the sixth, seventh and eight repetitions of the line “all I want's a good 5¢ seegar,” the voiceless alveolar sibilant /s/ (of “want's”) is extended to almost 2 seconds in length. In this most playful and dramatic rendering, other sounds are also prolonged, similarly moving towards the edge between phoneme and non-lexical groans. Given that the poem relates to a Seneca sweat-lodge ceremony, it's tempting to hear the acoustic emphasis on the prolonged /s/ as having an iconic relationship to water steaming off a heated stone. This level of meaning is not strongly evoked by the print poem. Of course, with a single, short poem and several variants to consider, we could also listen repeatedly to all three of these, but it seems unlikely we'd notice the particularities of these differences without at least taking the time to make full ethnopoetic transcriptions. But then, without using ARLO to assist in distant listening, we might not have flagged these poems as interesting variants in the first place. Thus what remains most intriguing is the possibility of using the metadata to construct these kinds of ARLO queries with the whole of a poet's recorded works, or even across a whole archive like Pennsound.
If we intuitively recognize that some readings are more dynamic than others, that some versions come across as readings while others constitute emergent performances, then there are a number of broad questions worth exploring in the future: What kinds of variations are introduced when a poet reads a given poem several times over a year? Are there patterns in the way a given poet reads when in front of a library audience in contrast with the performance in a coffee-house or bar, lecture hall, gallery, recording studio, bookstore? Does the featured reader perform differently than when participating in a group reading? Are there characteristics of home-town-crowd readings versus those given on the road? Does the poet perform differently when reading fresh poems from manuscript and when the poem has already been released in a print collection? Do readings of a poem vary at first and then settle into something like a static performance pattern? Do readings of a poem tend to increase or decrease in pace over time? Do they become more or less dynamic? Do asides and variant lines appear randomly or are they influenced by the site and occasion? Do the answers to the above questions conform to or challenge dominant notions of gender, style, region, etc.? To the extent that we find it interesting to pursue such questions, we will be using computational analysis and visualization tools like ARLO to help us frame the answers.
1. The project also involves programming and design work to repurpose the tool for the analysis of human voice files. https://blogs.ischool.utexas.edu/hipstas/
2. In this essay "Elaborative Versionings: Characteristics of Emergent Performance in Three Print/ Oral/Aural Poets" Oral Tradition, Center For Studies in Oral Tradition, University of Missouri-Columbia 21:1 (March 2006) I use analysis and transcription of the audio recordings of poetry performances in order to argue that several emergent features mark certain poetry readings as performative; however, in this piece, the analysis works at the level of close-listening by using manual transcription. See also Sherwood, Kenneth. (2000). The Audible Word: Sounding the Range of Twentieth-century American Poetics. Dissertation. SUNY at Buffalo. "'Sound Written and Sound Breathing': Versions of Vicuña's Palpable Poetics." The Precarious: The Art and Poetry of Cecilia Vicuña. Ed. M. Catherine de Zegher. Middletown: Wesleyan U P, 1997. 73-93.
3. The terms adopted by the Text Encoding Initiative for tagging vocal features seem most workable here, particularly as I think spectral analysis and visualization tools might also be adaptable to transcription and markup projects in the future. The availability of archived materials and the possibilities of analysis and visualization offered by structured data appear to justify a movement away from the eccentricities of Ethnopoetic transcription, as discussed in “Elaborative Versionings” and towards transcription and standardized markup using XML/TEI.
4. To some degree, I recognized that it is possible to ask such questions on a small scale without the incorporation of ARLO as a tool for visualization and analysis. In the LP and cassette era, one might access two or three performances of the same poem over time, listen to each, and make notations about what one heard. Pennsound provides many variant performances by the authors of a given poem, which I call versions. Elsewhere I have explored the way in which two particular kinds of difference, elaboration and versioning , can be appreciated as indicators of an emergent performance and identified through careful transcription. For those who have transcribed speech — particularly using any notational system that marks paralinguistic features — it won't be necessary to emphasize that this can be a slow, painstaking process. It "tunes" the ears of the listener but it does not "scale-up" to an archive with thousands of hours of poetry audio.
5. As invaluable as this resource has been, it should be said that the metadata and interface to Pennsound could be redesigned with significant benefit to scholars interested in working with the materials. One hopes that Pennsound will ultimately secure grant funding to implement a robust, repository style database-structure and more flexible search and navigational tools.
6. Rothenberg, Jerome. “Old Man Beaver's Blessing Song.” Seneca Journal. NY: New Directions, 1978. P. 9. Reprinted in New and Selected Poems.
7. A screen capture of the ARLO interface with these calibration settings among others: https://media.sas.upenn.edu/jacket2/images/Clipping/Sherwood-ARLO-Settin...
8. These settings are the result of trial and error; I do not consider them definitive for this kind of searching.
9. An PDF file of the query results for the analysis of two Rothenberg readings: https://media.sas.upenn.edu/jacket2/pdf/Sherwood-Kenneth_Distanced-Sound...
10. This preliminary work with ARLO leaves open a number of technical and methodological questions as well. Is segmentation via utterance to be preferred over automated, random tagging in the generation of the base set? Is it feasible to automate the generation of uttrance tags using machine learning? Exactly which perceived vocal features do the various ARLO parameters emphasize? Can we construct queries which more effectively isolate certain paralinguistic features (such as pitch range or tempo) in making these comparisions?
Kenneth Sherwood is Associate Professor of English at Indiana University of Pennsylvania, where he teaches and writes about poetics, oral performance, and digital writing and serves as co-director of the Center for Digital Humanities and Culture. He edited poet Louis Zukofsky's A Useful Art Essays and Radio Scripts on American Design (Wesleyan UP, 2003) and has published several chapbooks of poetry. His engagement with digital culture and writing dates back to 1993, when he co-founded the first “e-zine” of postmodern literature at SUNY Buffalo, where he earned graduate degrees through the Poetics program.
{kind=link}