
Clipping

The Sir George Williams University Poetry Reading Series ran from 1965 to 1974 in Montreal at what is now Concordia University, featuring live performances by prominent North American poets, including Beat poets, Black Mountain poets, and members of the western Canadian poetry collective TISH. Curated and organized primarily by professors in the English department, the series hosted over sixty poets during its eight-year run, bringing local writers into contact with regional, national, and international contemporaries. The university’s state-of-the-art audio-visual department was enlisted to record the series on Mylar 1 mil. tape using reel-to-reel tape machines. These recordings were digitized by the Concordia University Archives and transcribed by the SpokenWeb project in 2010, and have been made available online at spokenweb.ca.
As these sonic artifacts enter a digital environment we are interested in interrogating the sonic, conceptual, and historical possibilities afforded by this new medium. On one hand, Digital Audio Workstations allow us to isolate, visualize, and transform the minutiae of sonic matter, from the phoneme to the sibilant, as well as nonsemantic, environmental, and ambient sounds. On the other, aggregating and indexing the series’ recordings presents new opportunities for comparative and relational listening — thinking, for example, about the formal qualities of the poetry reading in terms of its length and structure, or analyzing the content of extrapoetic speech across speakers of different groups.
In the spring of 2018, we were invited to curate a selection of sound from the SGWU Poetry Series archive that would play as an installation in stairwells of Concordia University’s library. We each made a selection of recordings that explored some facet of the digital archive’s affordances. Below are some brief statements about our curatorial approaches and outcomes.
Jason Camlot: Curating the Signal
A poem is read out loud in a room of people. Sounds are produced, transduced through a microphone into electrical currents that pass through the coil of an electromagnet (in this case, the recording head of a reel-to-reel tape machine), a magnetic field is formed according to the patterns of the current sent from the source (the poet’s mouth), and a length of tape coated with iron oxide spools by the recording head, becoming magnetized according to the patterns of the sound signal’s moment. My approach to curating the documented sounds of the Sir George Williams Poetry Series has been inspired by some very elementary thinking about the relationship between sound and signal, and how digitally developed visual representations of sounds (digital sound signals) may invite us to focus on the sounds we are trained, in listening, not to hear. The unwanted sounds, mechanical glitches and squeaks, the disruptive sounds of bodily upheavals, hisses and pops and other forms of meaningless noise. Where does the digital sound signal take us in our exercise of listening to a documented literary event? In this first instance, it may lead us behind the curtain of speech to the sounds, vocal and otherwise, that speech so effectively conceals. It may lead us past semantics, to sound in some more basic sense that is at once more concrete and more abstract than the sound of a voice talking or reading.
A sound is produced when a source object vibrates in a manner that causes the surrounding air to move, and when those vibrations are of such a quality that they can be heard by a perceiving entity (for our purposes, a human being with the capacity to hear). The oscillation rate of the source determines what is called the frequency of the sound wave, and is characterized in hearing as the pitch of the sound. The degree of compression and rarefaction created by the source’s motion determines what is called the amplitude of the sound wave, and refers to the loudness of the sound when it is perceived. The ear hears these vibratory waves as sounds due to its capacity as a tympanic mechanism for transducing vibrations. We measure the frequency of sounds according to their rate of oscillation in hertz (Hz) and kilohertz (kHz) or cycles per second. Most humans can hear frequencies within the range of 20 Hz to 20,000 Hz [20 kHz]. Human voices typically range from 85–180 Hz (male) and 165–260 Hz (female). We measure the amplitude (loudness) of sounds in decibels (dB), a method of representing the ratio of one sound in relation to another, of metering the volume of sound as a signal.
When we refer to the sound, we are often speaking metaphorically, in the terms of the signal. An audio signal is a representation of a sound. There is a long and fascinating history informing the development and use of audio signals, from Édouard-Léon Scott de Martinville’s attempts to read smoke-blackened phonautograph sheets for discernible traces of vocal movement (c1857), to Herman von Helmholtz’s development of the powerful signal metaphor of the sound wave (c1863), to the back-lit needles of the Vu meters used to measure the amplitude of the sound signal on recording consoles and stereo devices since the 1940s. Digital signal processing and its inventive array of visual representations of discernible elements of sound (including frequency, amplitude, pitch, and many other sonic qualities) can be understood as the new media legacy of such early manifestations of sound signal visualization. Joseph Fourier’s concept of spectrum analysis (c1807), with its notion of expressing the signal as a combination of functions that can be interpreted in terms of frequency, would eventually develop into the most widely used signal representation for the purpose of analyzing speech, namely, the sound spectrograph (Bell Labs c1940).
I used an open source digital spectrogram tool — a visualization of the spectrum of frequencies of sounds captured during the Sir George Williams reading series events — with the aim of focusing on those visual cues that suggested sounds outside the typical frequency spectrum of human speech. In this two dimensional, spectral visualization the horizontal x axis represents time, the vertical y axis frequency, and the amplitude of a sound is apparent through color differentiation (the whiter the louder with the Audacity spectrogram). What would my collection of sounds from an audio-documented reading become if I removed all of the frequencies most typical of human speech, those tracking like a series of intense and discernible hoodoos of different shapes from the floor of the spectrogram upwards? What if I focused only on those shapes that floated like clouds and constellations, above the grounded visual cues?
In removing the floor of the y axis from my purview, I proceeded to isolate only those graphic representations of the sound spectrum that occurred outside the more typical values of human speech. These might be apparently floating sibilants or voiceless articulations that would have signified very differently within their holistic speech context (“S” and “T” sounds, guffaws),
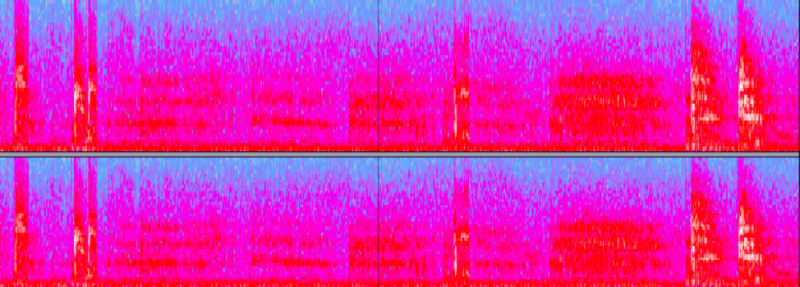 “T” Sounds and Breaths Visible as Thin White Vertical Lines and Floating Triadic Clouds with Audacity Spectogram, from recorded reading by Roy Kiyooka, Montreal, 2 December 1966
“T” Sounds and Breaths Visible as Thin White Vertical Lines and Floating Triadic Clouds with Audacity Spectogram, from recorded reading by Roy Kiyooka, Montreal, 2 December 1966
[Audio: Roy Kiyooka T Sounds and Breath SHORT CLIP]
they might be the notably diffuse spectra that appeared periodically during the course of a reading (laughter or applause),

A Diffuse Cloud of Laughter as Visible with Audacity Spectogram, from recorded reading by Robert Creeley, Montreal, 24 February 1967
[Audio: A Diffuse Cloud of Laughter - Robert Creeley 1967]
or they might be strangely uniform patterns in the upper registers of the spectrum signifying cryptic, mechanically produced patterns that, in most contexts of listening, would be identified as unwanted technical errors.
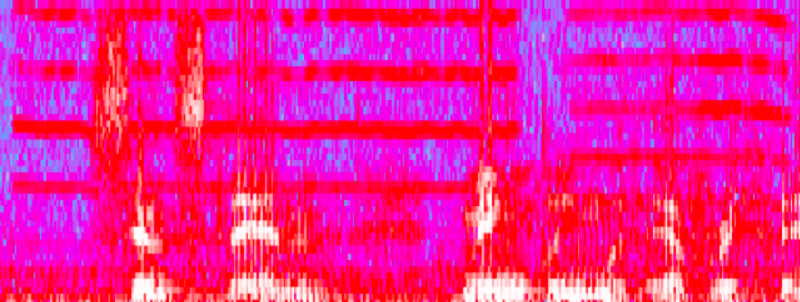 Mechanical Tape Squeak Visible as Uniform Horizontal Lines with Audacity Spectogram, from recorded reading by Robin Blaser, Montreal, 28 March 1969
Mechanical Tape Squeak Visible as Uniform Horizontal Lines with Audacity Spectogram, from recorded reading by Robin Blaser, Montreal, 28 March 1969
[Audio: Mechanical Tape Squeak - Robin Blaser 1969]
Sometimes I would identify a particular shape in the formants, and simply look for recurrent appearances of that shape across the recording, as with this series of “formant arches” that I found in the spectrogram representation of Dorothy Livesay’s reading of 14 January 1971. Here, my assumption of pattern is very much imposed upon the spectrogram and did not necessarily represent a recurrent index of any particular kind of sound.
 Perceived “Formant Arches” as Visible with Audacity Spectogram, from recorded reading by Dorothy Livesay, Montreal, 14 January 1971
Perceived “Formant Arches” as Visible with Audacity Spectogram, from recorded reading by Dorothy Livesay, Montreal, 14 January 1971
[Audio: Perceived Formant Arches – Dorothy Livesay 1971]
The result of this curatorial experiment that moves from selected patterns of the signal back to the concomitant sounds they index is a new audio document of sounds from a reading likely never heard before. The sounds of a historical reading event become strangely beautiful and creepy, corporeal and mechanical, socially-located and formally abstract, as much from the omission and silencing of the speech we would expect to hear as from the residual sounds that have been signaled to remain.
List of full clippings:
|
|
Clipping Title |
Time |
Artist |
|
1 |
4:40 |
Robert Creeley |
|
|
2 |
2:15 |
David McFadden |
|
|
3 |
3:28 |
John Newlove |
|
|
4 |
1:22 |
Dorothy Livesay |
|
|
5 |
0:33 |
Margaret Avison |
|
|
6 |
4:15 |
Jackson MacLow |
|
|
7 |
3:23 |
Roy Kiyooka |
|
|
8 |
5:25 |
Robin Blaser |
|
|
9 |
4:11 |
Margaret Atwood |
|
|
10 |
2:03 |
Earle Birney |
Deanna Fong: The Voice as Object
[Audio: The Voice in the Poetry Reading Series]
My path through the archive is informed by Mladen Dolar’s observation in A Voice and Nothing More (2006) that the voice is a trinity: it is at once the vehicle for the expression of symbolic meaning and the matter of physiological processes (that which produces the voice as an object of aesthetic admiration —“What a beautiful voice!”). More than these two things, however, the voice is a gap, a lack, an object (in the Lacanian sense), made evident whenever the voice cannot be reduced to one or the other of the former categories, which is always. Poetry’s uneasy relationship between the signs of language and the oral qualities of expression — rhythm, rhyme, meter, etc. — makes it an ideal site to sound the contours of this gap, as its recitation produces an effect that is greater than the sum of its causes. As listeners, we are moved by language, by sound, and an indescribable something else that emerges in their confluence.
To this end, I’ve isolated moments in the series where the voice is particularly resonant as an object — specifically, moments where the voice either fails as a vehicle for meaning, or surges with excess by indulging in its aesthetic qualities. At the beginning of her 1967 reading, Margaret Atwood apologizes that her voice has been othered by a disturbance in her physiology: she has caught “the Montreal plague” and finds herself channelling the husky voice of 1930s screen starlet Tallulah Bankhead. My inquiry into the vocal object begins here because, as Jacques Lacan reminds us, lack always begins in relation to an other. That is, while there is a certain symbolic investment in the voice as the guarantor of the subject’s coherency, our voices are never fully in our possession — they can be absented from the body through acousmatic technologies, they can be altered, misrecognized, or imitated.
At the same time, the voice can easily slide into the pleasurable circumlocutions of nonmeaning, as Maxine Gadd suggests in her 1972 reading with Andreas Schroder. She describes her practice of creating collaborative, improvisatory sound poems with members of Vancouver’s Intermedia group, which involved singing, chanting, and wailing, among other rhythmic and nonlinguistic vocal sounds. She notes how easily the sound of the voice can occlude meaning when she says, “You'd go around and you'd say, ‘Do you dig the poems?’ and they'd say, ‘I can't hear them, but we really like your voice.’” The other recordings in this curated selection hover between voice as vehicle and matter: Allen Ginsberg and Robert Duncan put their poems to song, self-consciously reflecting upon their voices as uncertain yet necessary mediators. Lionel Kearns and Robert Hogg probe the written poem’s relation to its recitation; Margaret Avison and Muriel Rukeyser point our attention to the breath upon which vocalization rests as the physical basis for all acts of communication.
List of speakers:
0:01 - Margaret Atwood (1974)
0:14 - Maxine Gadd (1972)
0:47 - Gwendolyn MacEwen (1966)
1:06 - Robert Hogg (1970)
1:32 - BpNichol (1968)
2:19 - Lionel Kearns (1968)
3:31 - Robert Kelly (1966)
4:28 - Robert Duncan (1968)
5:35 - Allen Ginsberg (1969)
6:19 - [Gladys] Maria Hindmarch (1969)
7:02 - Margaret Avison (1967)
7:44 - Muriel Rukeyser (1969)
Katherine McLeod: Interrupting Introductions
[Audio: Interrupting Introductions - Gwendolyn MacEwen Reading at the SGW Poetry Series, 1966]
Taking as its material the 1966 recording of Gwendolyn MacEwen and Phyllis Webb from the SGW Poetry Series, my audio clips perform interruptions by challenging the authority of the introduction as delivered by Roy Kiyooka. Taking the introductions — cutting them up — a cut, a syncope —interrupts the narrative created by the introductions for each reader and makes space for MacEwen’s and Webb’s voices to take control and introduce themselves. An interruption is a syncope, a cut, in sound that, as Catherine Clément describes, creates a palpable effect: “the syncope will always make a fuss: it cannot be discreet, it demands to be seen […] syncope is spectacle, it shows off, exposes itself, smashes, breaks, interrupts the daily course of other people's lives, people at whom the raptus is aimed” (Syncope: The Philosophy of Rapture). In each clipping, the interruptions stage what happens when the fictive authority of the introduction is exposed by the voices of the poets themselves.
[Audio: Interrupting Introductions - Phyllis Webb Reading at SGW Reading Series, 1966]
In each case, the clippings conclude with the phrases, “Ladies and gentlemen, Ms. Phyllis Webb” and, respectively, “Ladies and gentlemen, Gwendolyn MacEwen,” which suggests that the introduction has built towards the presentation of this writer herself but, in fact, the poet is already present and these clippings enact this presence with each poet speaking back against the introduction’s attempt to define who she is. As a result, in these clippings, MacEwen and Webb introduce themselves — an act that I hear as a feminist intervention particularly because they are the first female readers in the Sir George Williams Poetry Series and Kiyooka draws attention to that fact: “Now tonight it is my very great pleasure to introduce to you two poets whose distinctiveness is more than the fact of their sex.” Even though the introduction provides a frame for the clipping, I have deliberately removed this statement in its entirety, thereby removing the experience of having to sit quietly and uncomfortably while listening to it, but at the same time its presence in the original recording informs the feminist approach to the clippings as a way of speaking back to the authority of the introduction. Interestingly, in the introduction to MacEwen, Kiyooka defers to the bio that appears on the back of the vinyl record that he is holding, which has “a much more comprehensive biography of her.” When reading this bio, he reads, “she left school at eighteen” and adds “a high school dropout, as the sociologists would say,” eliciting an audible reaction from the audience. In the clipping I juxtapose this statement with MacEwen reading an introduction to one of her poems in which she speaks of limits (“Still not having exploited the animal kingdom”), which I offer as a hint at exhaustion that one could feel for an exploitation of a biographical detail being recited and reacted to in one’s presence as though one’s life is a spectacle.
Along with providing biographical information and often a rationale for the selected readers — and, in the case of this reading, an introduction to the poetry series itself — the introduction to a reading leads a listener into a reading in the sense of the definition of introduction: intro, to the inside; ducere, to lead. By interrupting the introduction, these clips question where this leads and what if, rather than leading in, the introduction remains in an interrupted place between, thereby letting specific phrases resonate there on their own (“This album will be released very shortly”) rather than leading to the poet herself. This approach performs, formally, a version of the spatial constraints of where this audio curation will be played as an installation: a stairway leading up to the Webster Library at Concordia University in Montreal. The stairway is a liminal space in which sound exists for listeners only in those in-between moments on their way up the stairs to the library or on their way back down the stairs, leaving a quiet space of reading and returning into a city of sounds. The stairway is an introduction; but, as a stairway filled with sound, that same space becomes an environment in which listeners could linger in that introduction, listening and following signals that might lead them somewhere else.