
Clipping

In the 2009 essay "Hearing Voices," Charles Bernstein writes that “a poet’s reading of her or his own work has an entirely different authority" from that of other readers. Bernstein assures his readers that his assertion is not "just another way of fetishizing the author and the author's voice" but rather a way of acknowledging that "the archive of recordings, as well as the live performance, of contemporary poems is almost exclusively composed of poets giving voice to their own work" (142). If the composition of the archive is almost exclusively concerned with the voice of the poet, the microphone is more catholic in its reach: when we listen to recordings of live poetry readings on PennSound, we hear many meaningful sounds and voices that are not the poet’s.
Even if the first intention of recording is to capture a poet’s voice, the microphone also captures the hum of air conditioners, the imperfections of recording devices, and the shuffle of papers, along with the sounds of the people in the audience: their applause, fidgeting, gasps, sighs, laughter, and voices. We do not just hear the voice of the poet, for we also hear others hearing, experiencing, and audibly responding.
During the HiPSTAS institute, I began work on a project that uses the machine-learning tool ARLO (Adaptive Recognition with Layered Optimization) to identify compelling moments of audience response in the PennSound archive. ARLO uses the algorithms of machine learning and the power of supercomputing to search sound with sound. The tool was originally designed for ornithological work: by tagging multiple instances of a birdcall, a researcher can train ARLO to identify other instances of that birdcall in an archive of field recordings.[1] In my initial explorations of audience response, my birdcall has been audience laughter and my field recordings have been poetry readings on PennSound. By using ARLO’s “distant listening,” I search for moments of laughter that point to productive sites for “close listening,” including moments when self-fashioned serious poets tell jokes, moments when audiences find humor in poetry intended to be serious, and moments when audiences experience collective delight and humor in poetry that might not be revealed in private reading from the page.[2]
When audience members laugh in the midst of a poetry recording, they remind the listener that she is not listening to a monologic performance but to a dialogic exchange. [3] Audiences generally restrict their applause to conventional moments when applause is expected, and decorum prohibits most audience speech during a performance of poetry. When the audience laughs, though, it communicates directly with the poet in a way that enables slippages and intermixtures of intention and reception. The presence of laughter on a recording marks it as an ongoing social interaction, not a fragment of isolated poetic speech.
Listen, for example, to how differently the audience perceives William Carlos Williams’s “This Is Just To Say” from one reading to the next. At Harvard in 1951, Williams reads the short poem once then announces, giggling, that he’ll read it again. The repetition authorizes the audience’s laughter, which builds after the reading as Williams offers a series of jokes mocking the supercilious academics and buffoonish critics who would go so far as to read the depths of his psychology in a kitchen-note poem. [4] This laughter-filled reading contrasts sharply with a reading at the home of Eyvind Earle in the San Fernando Valley of California in 1950. Here, Williams brings much the same material he brings to the other reading: the same poem, even the same joke about psychoanalytic reading. Instead of laughing, though, the smaller audience reacts to the poem with quiet sobriety. The audiences’ choices to laugh or not to laugh at Williams’s poem and the jokes he tells about it dialogically transform the poem between various identities as a subtly taunting note between husband and wife, a simple song to simple pleasures, a problem-object for what counts as poetry, a poetic provocation that demonstrates the absurdity of critics, and an in-joke between poet and audience. [5]
I have little doubt that given enough time, a meticulous close listener would find hundreds of similarly charged moments of laughter in the thousands of hours of recorded poetry on PennSound. Most of us don’t have that time, though, and the task grows more imposing as PennSound grows. My initial experiments suggest that ARLO will be able to reveal a large number of sites for interpretation of audience laughter that I wouldn’t have been able to find through close listening alone.
I used a focused initial experiment to test ARLO's ability to recognize laughter if most variables, including the location of the reading, the voices of the audience members, the microphone, and the recording quality remained constant. By asking the computer to find laughter in a small set of files in which I knew many instances of laughter are to be found, I hoped to show that ARLO might be capable of identifying laughter in larger sets of files.
Though laughter may be relatively rare as a form of audience response in the entire PennSound archive, it occurs frequently in recordings of the early twenty-first century style of poetry known as Flarf. Gary Sullivan, the prime mover behind Flarf, describes it as “a kind of corrosive, cute, or cloying, awfulness” that is “Wrong. Un-P.C. Out of control. ‘Not okay’” (“Flarf Files”). Poets writing under the banner of Flarf sought to write the very worst poetry they could, and the results were forthrightly comic.
I started with the recording of a performance of K. Silem Mohammad's "Sonnagrams" at Studio One in Oakland on April 3, 2009. The Sonnagrams, anagrams of Shakespeare’s sonnets that nevertheless adhere to Shakespearean meter and rhyme scheme, had two distinct advantages for the purposes of this initial experiment: first, they are funny—in the first poem, Shakespeare’s “From fairest creatures we desire increase” finds itself transformed into “Hot Butt Hot Butt Hot Butt Diddy,” and the first quatrain contains references to “erotic reptiles,” “synthetic England’s deathly stench,” and “friendly hamsters [that] masturbate in French”—and second, the pause after each line leaves space for the audience to laugh.
On PennSound, the reading is broken into 16 segments—an introduction and fifteen readings of poems—each of which I converted to a WAV file and uploaded to ARLO. I proceeded to listen to and tag instances of audience laughter in the first seven of these files. The ARLO interface marks these “human tags” in green. The ARLO visualization of this segment of sound, for example, looks like this once I have marked the laughter as laughter:
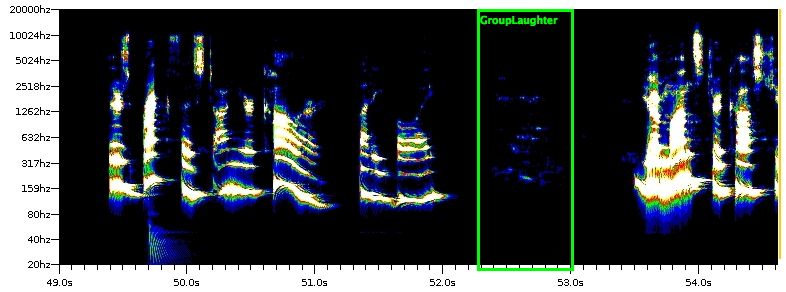
After I tagged the first seven files, I’d marked about 30 instances of audience laughter. Next, I set ARLO to work on a “supervised tag discovery” task. The “supervision” here comes from the human tags. The supercomputer looks for patterns in the human tags in the specified files and marks promising segments of sound with a “machine tag” that it marks in red. All the tags can be viewed via the catalog tool—here, the user deletes tags that do not represent the targeted sound and accepts tags that do. Human-accepted machine tags are marked in a purplish pink.

By accepting relevant tags and deleting ones that do not match human perception, the user teaches ARLO to think more like a human—in this case, to better match my perception of whether a tag sounds like a group laughing. Once tags have been accepted and deleted, supervised tag discovery can be run again, and because the machine has a larger set of human-approved data to work from, its results will improve.
The results of my initial experiment with the single performance of the Sonnagrams were promising. ARLO managed to find a large number of instances of laughter not just in the files I’d tagged, but also in the files I hadn’t. While ARLO returned a number of results that weren’t laughter, including instances of the poet speaking and the audience applauding, about half the returned results were indeed audience laughter, and the tool had proved to my satisfaction that it was at least capable of the task I had set for it. ARLO has successfully marked around 100 moments of laughter like this one, visualized below, and my only intervention was to feed it initial examples of laughter and to approve or reject its result.
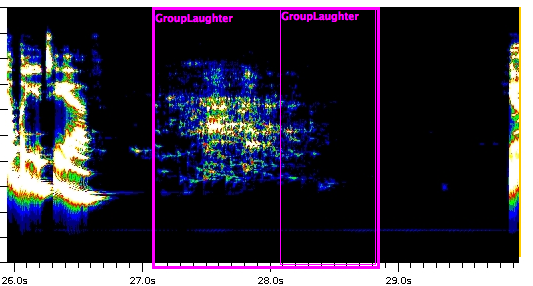
Now that I know ARLO can find laughter when other variables are controlled for, I’m scaling up the project. I’m in the midst of expanding my explorations to a larger set of Flarf poets whose recordings I know to be rich with laughter. Once I’ve figured out optimal settings for finding laughter in recordings across different spaces that record different audiences with different levels of recording quality, I’ll scale up again by tagging laughter in a large sample of files drawn more randomly from PennSound. Once I have a large, varied sample of human tags, I’ll put ARLO to work finding laughter in the entire PennSound archive. After the machine has helped me find laughter, I’ll set it aside to pursue the more traditionally humanistic research activities of listening, contextualizing, and interpreting.
It may be some time before a tool like ARLO can produce anything close to a comprehensive accounting of all the laughter on PennSound. At least for the time being, I’m better at hearing laughter than any computer is, and I’m happy to avoid any temptation to use quantitative methods as a pseudo-scientific measure of which poets are funniest or which audiences most prone to laughter. I’m nevertheless excited that ARLO offers a method to identify and explore audiences’ responses to a variety of poets reading on PennSound. By hearing the people on the peripheries of sound recordings and not just the people at the center of them, we can explore responses to voiced poetry as they are experienced not by imagined ideal readers but by actual historical listeners.
Eric Rettberg is a Marion L. Brittain Postdoctoral Fellow at the Georgia Institute of Technology. His research interests include seriousness and unseriousness in modernism and contemporary conceptualism, poetic sound, digital culture, and the digital humanities. His current book project is Ridiculous Modernisms, Outrageous Conceptualisms, and the Stakes of Literary Experiment.
[1] Ken Sherwood describes more history and technical detail of ARLO in his Clipping post on “Distant Sounding.” Tanya Clement, Loretta Auvil, and David Tcheng organized the HiPSTAS institute in part to see how humanities researchers might put such a tool to humanistic ends. Some HiPSTAS researchers interested in poetry have occupied themselves with the voices of poets. Sherwood’s essay, for example, uses ARLO to think through variation across a single poet’s readings. Marit MacArthur has been using ARLO and other tools to categorize prevalent poetic reading styles. Others have focused on finding meaning in the mechanical remnants of reading spaces, recording devices, and recording media. Chris Mustazza describes his work with ARLO and recording media in a prior Clipping post. Stephen McLaughlin is currently at work on a project to identify applause in the PennSound archive.
[2] I draw the term “close listening” from Charles Bernstein’s Close Listening (1998). Tanya Clement describes “Distant Listening,” which adapts Franco Moretti’s “Distant Reading” to sound, in “Distant Listening: On Data Visualizations…” and “Distant Listening to Gertrude Stein’s Melanctha.”
[3] In his article on the prehistory and history of the laugh track, Jacob Smith argues convincingly that the presence of a laughing interlocutor in late 19th- and early 20th- century “laughing song” recordings worked both to establish a sense of authenticity and to break the frame: “When the woman in the laughing record floods out, the one-to-one situation between listener and performer is altered, because there are now at least two audience members. The listener’s role is suddenly made uncertain, free-floating. …The listener has lost a certain formal connection with the performer but has gained a relationship to the laughing audience member, who has broached the ritual constraints of the situation” (28). I am grateful to Brandon Walsh for suggesting the relevance of Smith’s essay to my project.
[4] The audience laughs even more uproariously at a reading of “This Is Just To Say” at Princeton in 1952.
[5] An audience that is perceived to laugh “wrongly” at poetry changes the character of a reading even more drastically, as the event known as either “The World’s Most Annoying Poetry Reading” or “The Day Flarf Died” shows. In the course of that Ariana Reines reading from December 5, 2009, audience members call each other out for laughing in a way that makes other audience members uncomfortable, and the dialog and awkwardness over that laughter goes on at length. I am grateful to Morgan Myers for suggesting the relevance of this event to my project.
Works Cited
Bernstein, Charles, ed. Close Listening: Poetry and the Performed Word. Cary, NC: Oxford UP, 1998. Print.
Bernstein, Charles. “Hearing Voices.” Perloff, Marjorie and Dworkin, Craig, eds. The Sound of Poetry / The Poetry of Sound. Chicago: U of Chicago P, 2009. Print.
Clement, Tanya. “Distant Listening: On Data Visualisations and Noise in the Digital Humanities.”Digital Studies/Le Champ Numérique 3.2 (2013). Web.
Clement, Tanya, David Tcheng, Loretta Auvil, Boris Capitanu, and Joao Barbosa.“Distant Listening to Gertrude Stein’s ‘Melanctha’: Using Similarity Analysis in a Discovery Paradigm to Analyze Prosody and Author Influence.” Literary and Linguistic Computing 28.4 (2013): 582-602. Web.
Smith, Jacob. “The Frenzy of the Audible: Pleasure, Authenticity, and Recorded Laughter.” Television & New Media 6.1 (February 2005): 23-47. Print.
Magee, Michael, K. Silem Mohammad, and Gary Sullivan. “ The Flarf Files.” Electronic Poetry Center. 15 Mar. 2015. Web.
Mohammad, K. Silem. Sonnagrams 1-20. Cincinatti, OH: Slack Buddha Press, 2009. Print.